Einführung
Der gesamte Prozess des Data-Mining kann nicht in einem einzigen Schritt abgeschlossen werden. Mit anderen Worten, man kann die benötigten Informationen nicht einfach so aus den großen Datenmengen gewinnen. Es ist ein sehr komplexer Prozess, der eine Reihe von Vorgängen umfasst. Die Prozesse wie Datenbereinigung, Datenintegration, Datenauswahl, Datentransformation, Data Mining, Musterauswertung und Wissensrepräsentation müssen in der vorgegebenen Reihenfolge durchgeführt werden.
Typen von Data-Mining-Prozessen
Die verschiedenen Data-Mining-Prozesse lassen sich in zwei Typen einteilen: Datenvorbereitung oder Datenvorverarbeitung und Data Mining. Die ersten vier Prozesse, d.h. Datenbereinigung, Datenintegration, Datenauswahl und Datentransformation, werden als Datenvorbereitungsprozesse betrachtet. Die letzten drei Prozesse, einschließlich Data Mining, Musterauswertung und Wissensrepräsentation, werden in einen Prozess namens Data Mining integriert.
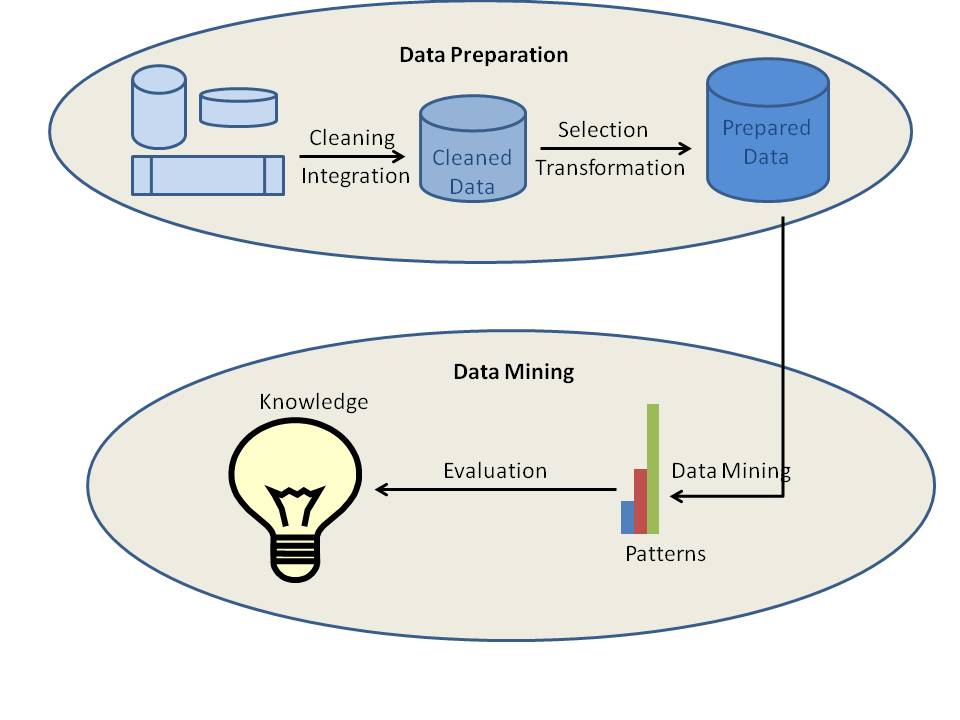
a) Datenbereinigung
Datenbereinigung ist der Prozess, bei dem die Daten bereinigt werden. Die Daten in der realen Welt sind normalerweise unvollständig, verrauscht und inkonsistent. Den in Datenquellen verfügbaren Daten können Attributwerte, Daten von Interesse usw. fehlen. Wenn Sie zum Beispiel demografische Daten von Kunden benötigen und die verfügbaren Daten keine Attribute für das Geschlecht oder das Alter der Kunden enthalten, sind die Daten natürlich unvollständig. Dann sind die Daten natürlich unvollständig. Manchmal können die Daten auch Fehler oder Ausreißer enthalten. Ein Beispiel ist ein Altersattribut mit dem Wert 200. Es ist offensichtlich, dass der Alterswert in diesem Fall falsch ist. Die Daten können auch inkonsistent sein. Zum Beispiel könnte der Name eines Mitarbeiters in verschiedenen Datentabellen oder Dokumenten unterschiedlich gespeichert sein. In diesem Fall sind die Daten inkonsistent. Wenn die Daten nicht sauber sind, sind die Data-Mining-Ergebnisse weder zuverlässig noch genau.
Die Datenbereinigung umfasst eine Reihe von Techniken, darunter das manuelle Auffüllen der fehlenden Werte, die kombinierte Überprüfung durch Computer und Mensch usw. Das Ergebnis des Datenbereinigungsprozesses sind angemessen bereinigte Daten.
b) Datenintegration
Datenintegration ist der Prozess, bei dem Daten aus verschiedenen Datenquellen in eine einzige integriert werden. Daten liegen in verschiedenen Formaten an verschiedenen Orten. Daten können in Datenbanken, Textdateien, Tabellenkalkulationen, Dokumenten, Datenwürfeln, im Internet und so weiter gespeichert sein. Die Datenintegration ist eine wirklich komplexe und knifflige Aufgabe, da die Daten aus verschiedenen Quellen normalerweise nicht übereinstimmen. Angenommen, eine Tabelle A enthält eine Entität namens customer_id, während eine andere Tabelle B eine Entität namens number enthält. Es ist wirklich schwierig sicherzustellen, ob sich diese beiden Entitäten auf denselben Wert beziehen oder nicht. Metadaten können effektiv genutzt werden, um Fehler im Datenintegrationsprozess zu reduzieren. Ein weiteres Problem ist die Datenredundanz. Dieselben Daten können in verschiedenen Tabellen in derselben Datenbank oder sogar in verschiedenen Datenquellen vorhanden sein. Bei der Datenintegration wird versucht, die Redundanz so weit wie möglich zu reduzieren, ohne die Zuverlässigkeit der Daten zu beeinträchtigen.
c) Datenauswahl
Data-Mining-Prozesse erfordern große Mengen an historischen Daten für die Analyse. Daher enthält der Datenspeicher mit integrierten Daten in der Regel viel mehr Daten als tatsächlich benötigt werden. Aus den verfügbaren Daten müssen die Daten, die von Interesse sind, ausgewählt und gespeichert werden. Die Datenauswahl ist der Prozess, bei dem die für die Analyse relevanten Daten aus der Datenbank abgerufen werden.
d) Datentransformation
Die Datentransformation ist der Prozess der Umwandlung und Konsolidierung der Daten in verschiedene Formen, die für die Auswertung geeignet sind. Die Datentransformation umfasst normalerweise Normalisierung, Aggregation, Generalisierung usw. Zum Beispiel kann ein Datensatz, der als “-5, 37, 100, 89, 78” vorliegt, in “-0,05, 0,37, 1,00, 0,89, 0,78” umgewandelt werden. Dadurch werden die Daten für das Data Mining besser geeignet. Nach der Datenintegration sind die verfügbaren Daten bereit für Data Mining.
e) Data Mining
Data Mining ist der Kernprozess, bei dem eine Reihe komplexer und intelligenter Methoden angewendet werden, um Muster aus Daten zu extrahieren. Der Data-Mining-Prozess umfasst eine Reihe von Aufgaben wie Assoziation, Klassifizierung, Vorhersage, Clustering, Zeitreihenanalyse usw.
f) Musterauswertung
Die Musterauswertung identifiziert die wirklich interessanten Muster, die das Wissen auf der Grundlage verschiedener Arten von Interessensmaßen darstellen. Ein Muster gilt als interessant, wenn es potenziell nützlich ist, von Menschen leicht verstanden werden kann, eine Hypothese bestätigt, die jemand bestätigen möchte, oder mit einem gewissen Grad an Sicherheit auf neue Daten anwendbar ist.
g) Wissensdarstellung
Die aus den Daten gewonnenen Informationen müssen dem Benutzer auf ansprechende Weise präsentiert werden. Verschiedene Wissensrepräsentations- und Visualisierungstechniken werden angewandt, um den Benutzern die Ergebnisse des Data Mining zur Verfügung zu stellen.
Zusammenfassung
Die Datenaufbereitungsmethoden zusammen mit den Data-Mining-Aufgaben vervollständigen den Data-Mining-Prozess als solchen. Der Data-Mining-Prozess ist nicht so einfach, wie wir ihn erklären. Jeder Data-Mining-Prozess ist mit einer Reihe von Herausforderungen und Problemen im realen Leben konfrontiert und extrahiert potenziell nützliche Informationen.