Introduction
L’ensemble du processus d’exploration de données ne peut pas être achevé en une seule étape. En d’autres termes, vous ne pouvez pas obtenir les informations requises à partir des grands volumes de données aussi simplement que cela. C’est un processus très complexe que nous pensons impliquant un certain nombre de processus. Les processus comprenant le nettoyage des données, l’intégration des données, la sélection des données, la transformation des données, l’exploration des données, l’évaluation des modèles et la représentation des connaissances doivent être complétés dans l’ordre donné.
Types de processus d’exploration des données
Les différents processus d’exploration des données peuvent être classés en deux types : la préparation des données ou le prétraitement des données et l’exploration des données. En fait, les quatre premiers processus, qui sont le nettoyage des données, l’intégration des données, la sélection des données et la transformation des données, sont considérés comme des processus de préparation des données. Les trois derniers processus, y compris l’exploration des données, l’évaluation des modèles et la représentation des connaissances sont intégrés dans un seul processus appelé exploration des données.
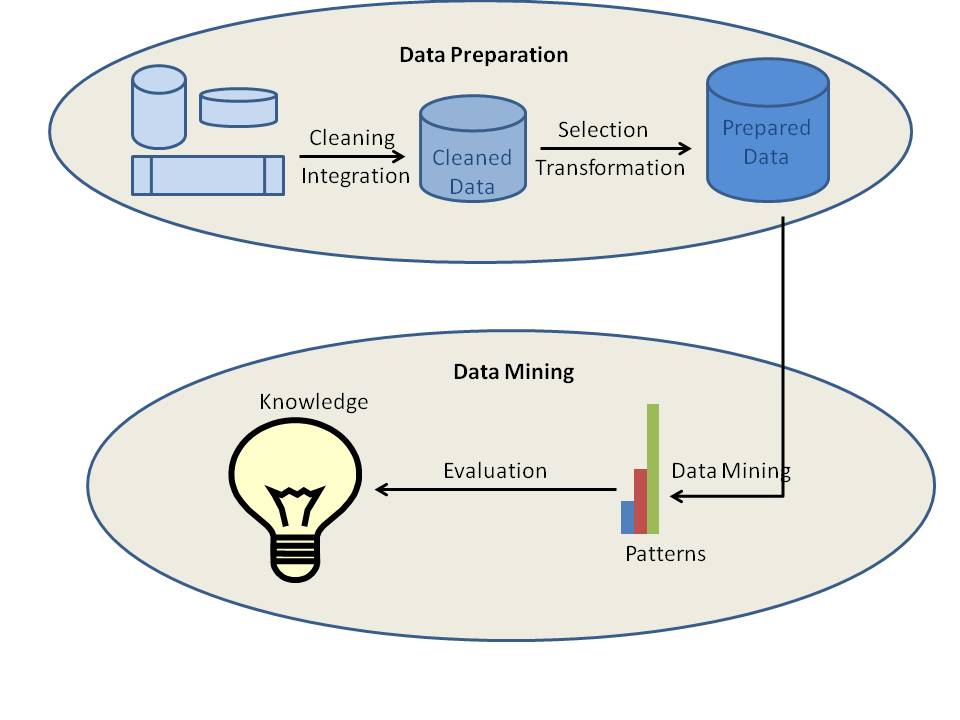
a) Nettoyage des données
Le nettoyage des données est le processus où les données sont nettoyées. Les données dans le monde réel sont normalement incomplètes, bruyantes et incohérentes. Les données disponibles dans les sources de données peuvent manquer de valeurs d’attributs, de données d’intérêt, etc. Par exemple, vous voulez les données démographiques des clients et si les données disponibles ne comprennent pas d’attributs pour le sexe ou l’âge des clients ? Dans ce cas, les données sont bien sûr incomplètes. Parfois, les données peuvent contenir des erreurs ou des valeurs aberrantes. Prenons l’exemple d’un attribut d’âge dont la valeur est 200. Il est évident que la valeur de l’âge est erronée dans ce cas. Les données peuvent également être incohérentes. Par exemple, le nom d’un employé peut être enregistré différemment dans différentes tables de données ou documents. Dans ce cas, les données sont incohérentes. Si les données ne sont pas propres, les résultats de l’exploration de données ne seraient ni fiables ni précis.
Le nettoyage des données implique un certain nombre de techniques, y compris le remplissage manuel des valeurs manquantes, l’inspection combinée informatique et humaine, etc. Le résultat du processus de nettoyage des données est des données nettoyées de manière adéquate.
b) Intégration des données
L’intégration des données est le processus où les données de différentes sources de données sont intégrées en une seule. Les données se trouvent dans différents formats à différents endroits. Les données peuvent être stockées dans des bases de données, des fichiers texte, des feuilles de calcul, des documents, des cubes de données, Internet et ainsi de suite. L’intégration des données est une tâche vraiment complexe et délicate car les données provenant de différentes sources ne correspondent pas normalement. Supposons qu’une table A contienne une entité nommée customer_id alors qu’une autre table B contient une entité nommée number. Il est vraiment difficile de s’assurer que ces deux entités font référence à la même valeur ou pas. Les métadonnées peuvent être utilisées efficacement pour réduire les erreurs dans le processus d’intégration des données. Un autre problème rencontré est la redondance des données. Les mêmes données peuvent être disponibles dans différentes tables de la même base de données ou même dans différentes sources de données. L’intégration de données essaie de réduire la redondance au niveau maximum possible sans affecter la fiabilité des données.
c) Sélection des données
Le processus d’exploration de données nécessite de grands volumes de données historiques pour l’analyse. Donc, généralement, le référentiel de données intégrées contient beaucoup plus de données que ce qui est réellement nécessaire. Parmi les données disponibles, les données d’intérêt doivent être sélectionnées et stockées. La sélection des données est le processus où les données pertinentes pour l’analyse sont extraites de la base de données.
d) Transformation des données
La transformation des données est le processus de transformation et de consolidation des données sous différentes formes qui conviennent à l’exploitation minière. La transformation des données implique normalement la normalisation, l’agrégation, la généralisation, etc. Par exemple, un ensemble de données disponibles comme “-5, 37, 100, 89, 78” peut être transformé en “-0,05, 0,37, 1,00, 0,89, 0,78”. Les données deviennent alors plus adaptées à l’exploration de données. Après l’intégration des données, les données disponibles sont prêtes pour le data mining.
e) Data Mining
Le data mining est le processus central où un certain nombre de méthodes complexes et intelligentes sont appliquées pour extraire des modèles à partir de données. Le processus d’exploration de données comprend un certain nombre de tâches telles que l’association, la classification, la prédiction, le regroupement, l’analyse de séries chronologiques, etc.
f) Évaluation des motifs
L’évaluation des motifs identifie les motifs réellement intéressants représentant des connaissances sur la base de différents types de mesures d’intérêt. Un motif est considéré comme intéressant s’il est potentiellement utile, facilement compréhensible par les humains, valide une certaine hypothèse que quelqu’un veut confirmer ou valide sur de nouvelles données avec un certain degré de certitude.
g) Représentation des connaissances
L’information extraite des données doit être présentée à l’utilisateur d’une manière attrayante. Différentes techniques de représentation et de visualisation des connaissances sont appliquées pour fournir le résultat de l’exploration de données aux utilisateurs.
Summary
Les méthodes de préparation des données ainsi que les tâches d’exploration de données complètent le processus d’exploration de données en tant que tel. Le processus de data mining n’est pas aussi simple que nous l’expliquons. Chaque processus d’exploration de données fait face à un certain nombre de défis et de problèmes dans un scénario de vie réelle et extrait des informations potentiellement utiles.