Introduzione
L’intero processo di data mining non può essere completato in un solo passo. In altre parole, non è possibile ottenere le informazioni richieste dai grandi volumi di dati in modo così semplice. È un processo molto complesso che coinvolge una serie di processi. I processi che includono la pulizia dei dati, l’integrazione dei dati, la selezione dei dati, la trasformazione dei dati, l’estrazione dei dati, la valutazione dei modelli e la rappresentazione della conoscenza devono essere completati nell’ordine dato.
Tipi di processi di estrazione dei dati
I diversi processi di estrazione dei dati possono essere classificati in due tipi: preparazione dei dati o pre-elaborazione dei dati e estrazione dei dati. Infatti, i primi quattro processi, che sono la pulizia dei dati, l’integrazione dei dati, la selezione dei dati e la trasformazione dei dati, sono considerati come processi di preparazione dei dati. Gli ultimi tre processi che includono l’estrazione dei dati, la valutazione dei modelli e la rappresentazione della conoscenza sono integrati in un unico processo chiamato estrazione dei dati.
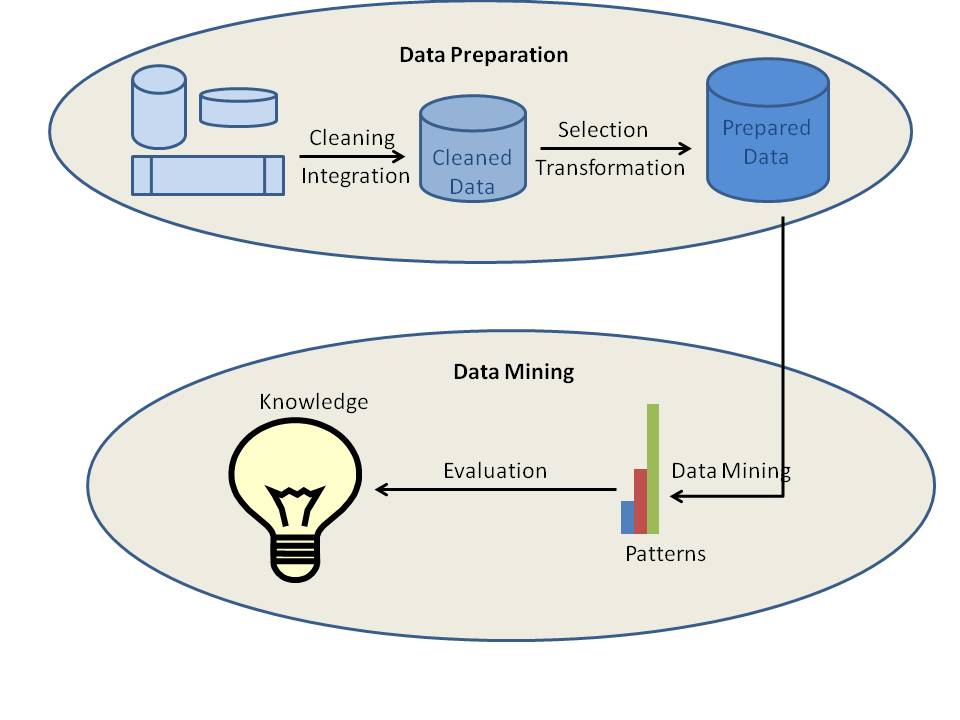
a) Pulizia dei dati
La pulizia dei dati è il processo in cui i dati vengono puliti. I dati nel mondo reale sono normalmente incompleti, rumorosi e inconsistenti. I dati disponibili nelle fonti di dati potrebbero mancare di valori di attributi, dati di interesse, ecc. Per esempio, volete i dati demografici dei clienti e cosa succede se i dati disponibili non includono attributi per il sesso o l’età dei clienti? Allora i dati sono ovviamente incompleti. A volte i dati potrebbero contenere errori o outlier. Un esempio è un attributo di età con valore 200. È ovvio che il valore dell’età è sbagliato in questo caso. I dati potrebbero anche essere incoerenti. Per esempio, il nome di un dipendente potrebbe essere memorizzato diversamente in diverse tabelle di dati o documenti. Qui, i dati sono incoerenti. Se i dati non sono puliti, i risultati del data mining non sarebbero né affidabili né accurati.
La pulizia dei dati implica una serie di tecniche che includono il riempimento manuale dei valori mancanti, l’ispezione combinata di computer e uomo, ecc. L’output del processo di pulizia dei dati è dati adeguatamente puliti.
b) Integrazione dei dati
L’integrazione dei dati è il processo in cui i dati provenienti da diverse fonti di dati sono integrati in uno. I dati si trovano in formati diversi in luoghi diversi. I dati potrebbero essere memorizzati in database, file di testo, fogli di calcolo, documenti, cubi di dati, Internet e così via. L’integrazione dei dati è un compito davvero complesso e difficile perché i dati provenienti da fonti diverse non corrispondono normalmente. Supponiamo che una tabella A contenga un’entità chiamata customer_id, mentre un’altra tabella B contiene un’entità chiamata numero. È davvero difficile assicurare che entrambe queste entità si riferiscano allo stesso valore o meno. I metadati possono essere usati efficacemente per ridurre gli errori nel processo di integrazione dei dati. Un altro problema affrontato è la ridondanza dei dati. Gli stessi dati potrebbero essere disponibili in diverse tabelle nello stesso database o anche in diverse fonti di dati. L’integrazione dei dati cerca di ridurre la ridondanza al massimo livello possibile senza influenzare l’affidabilità dei dati.
c) Selezione dei dati
Il processo di data mining richiede grandi volumi di dati storici da analizzare. Quindi, di solito il repository di dati con dati integrati contiene molti più dati di quelli effettivamente necessari. Dai dati disponibili, i dati di interesse devono essere selezionati e memorizzati. La selezione dei dati è il processo in cui i dati rilevanti per l’analisi vengono recuperati dal database.
d) Trasformazione dei dati
La trasformazione dei dati è il processo di trasformazione e consolidamento dei dati in forme diverse che sono adatte al mining. La trasformazione dei dati normalmente comporta normalizzazione, aggregazione, generalizzazione ecc. Per esempio, una serie di dati disponibili come “-5, 37, 100, 89, 78” può essere trasformata come “-0.05, 0.37, 1.00, 0.89, 0.78”. Qui i dati diventano più adatti al data mining. Dopo l’integrazione dei dati, i dati disponibili sono pronti per il data mining.
e) Data Mining
Il data mining è il processo centrale in cui un certo numero di metodi complessi e intelligenti sono applicati per estrarre modelli dai dati. Il processo di data mining include una serie di compiti come l’associazione, la classificazione, la predizione, il clustering, l’analisi delle serie temporali e così via.
f) Pattern Evaluation
La valutazione dei pattern identifica i pattern veramente interessanti che rappresentano la conoscenza sulla base di diversi tipi di misure di interesse. Un pattern è considerato interessante se è potenzialmente utile, facilmente comprensibile dagli esseri umani, convalida qualche ipotesi che qualcuno vuole confermare o valida su nuovi dati con un certo grado di certezza.
g) Knowledge Representation
Le informazioni estratte dai dati devono essere presentate all’utente in un modo attraente. Diverse tecniche di rappresentazione e visualizzazione della conoscenza sono applicate per fornire l’output del data mining agli utenti.
Sommario
I metodi di preparazione dei dati insieme ai compiti di data mining completano il processo di data mining come tale. Il processo di data mining non è così semplice come spiegato. Ogni processo di data mining affronta una serie di sfide e problemi nello scenario della vita reale ed estrae informazioni potenzialmente utili.
.