Indledning
Hele processen med data mining kan ikke gennemføres i et enkelt trin. Med andre ord kan du ikke få de nødvendige oplysninger fra de store mængder af data så simpelt som det. Det er en meget kompleks proces, end vi tror, der involverer en række processer. Processerne, herunder datarengøring, dataintegration, dataudvælgelse, datatransformation, datamining, mønstervurdering og vidensrepræsentation, skal gennemføres i den givne rækkefølge.
Typer af dataminingprocesser
De forskellige dataminingprocesser kan inddeles i to typer: datapræparering eller dataprebehandling og datamining. Faktisk betragtes de første fire processer, dvs. datarengøring, dataintegration, dataudvælgelse og datatransformation, som datapræparationsprocesser. De sidste tre processer, herunder data mining, mønstervurdering og vidensrepræsentation, er integreret i én proces kaldet data mining.
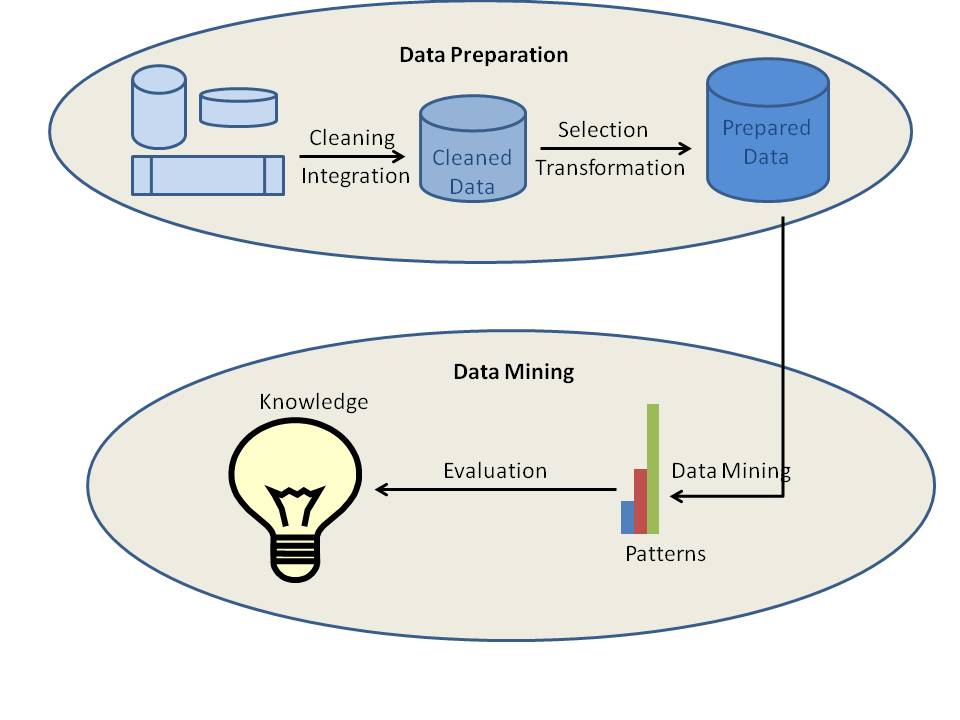
a) Datarengøring
Datarengøring er den proces, hvor dataene bliver renset. Data i den virkelige verden er normalt ufuldstændige, støjende og inkonsekvente. De data, der er tilgængelige i datakilderne, kan mangle attributværdier, data af interesse osv. Du ønsker f.eks. demografiske data om kunder, og hvad nu, hvis de tilgængelige data ikke indeholder attributter for kundernes køn eller alder? Så er dataene naturligvis ufuldstændige. Nogle gange kan dataene indeholde fejl eller outliers. Et eksempel er en aldersattribut med værdien 200. Det er indlysende, at aldersværdien er forkert i dette tilfælde. Dataene kan også være inkonsekvente. F.eks. kan navnet på en medarbejder være gemt forskelligt i forskellige datatabeller eller dokumenter. Her er dataene inkonsistente. Hvis dataene ikke er rene, vil data mining-resultaterne hverken være pålidelige eller nøjagtige.
Datarengøring omfatter en række teknikker, herunder udfyldelse af manglende værdier manuelt, kombineret computer- og menneskelig inspektion osv. Resultatet af datarensningsprocessen er tilstrækkeligt rensede data.
b) Dataintegration
Dataintegration er den proces, hvor data fra forskellige datakilder integreres i én. Data ligger i forskellige formater på forskellige steder. Data kan være gemt i databaser, tekstfiler, regneark, dokumenter, datakuber, internet osv. Dataintegration er en virkelig kompleks og vanskelig opgave, fordi data fra forskellige kilder ikke passer normalt sammen. Lad os antage, at en tabel A indeholder en enhed ved navn customer_id, mens en anden tabel B indeholder en enhed ved navn number. Det er virkelig svært at sikre, om begge disse enheder henviser til den samme værdi eller ej. Metadata kan bruges effektivt til at reducere fejl i dataintegrationsprocessen. Et andet problem er dataredundans. De samme data kan være tilgængelige i forskellige tabeller i den samme database eller endda i forskellige datakilder. Dataintegration forsøger at reducere redundans til det højest mulige niveau uden at påvirke pålideligheden af dataene.
c) Dataudvalg
Data mining-processen kræver store mængder historiske data til analyse. Så normalt indeholder dataregistret med integrerede data langt flere data, end der egentlig er behov for. Ud fra de tilgængelige data skal de data, der er af interesse, udvælges og lagres. Dataudvælgelse er den proces, hvor de data, der er relevante for analysen, hentes fra databasen.
d) Datatransformation
Datatatransformation er processen med at omdanne og konsolidere dataene til forskellige former, der er egnede til mining. Datatransformation omfatter normalt normalisering, aggregering, generalisering osv. F.eks. kan et datasæt, der foreligger som “-5, 37, 100, 89, 78”, omdannes til “-0,05, 0,37, 1,00, 0,89, 0,78”. Her bliver dataene mere velegnede til data mining. Efter dataintegration er de tilgængelige data klar til data mining.
e) Data Mining
Data mining er den centrale proces, hvor en række komplekse og intelligente metoder anvendes til at udtrække mønstre fra data. Data mining-processen omfatter en række opgaver som f.eks. association, klassificering, forudsigelse, clustering, tidsserieanalyse osv.
f) Mønstervurdering
Mønstervurderingen identificerer de virkelig interessante mønstre, der repræsenterer viden baseret på forskellige typer af interessemålinger. Et mønster anses for at være interessant, hvis det er potentielt nyttigt, let forståeligt for mennesker, validerer en hypotese, som nogen ønsker at bekræfte, eller er gyldigt på nye data med en vis grad af sikkerhed.
g) Vidensrepræsentation
Den information, der er udvundet fra dataene, skal præsenteres for brugeren på en tiltalende måde. Forskellige vidensrepræsentations- og visualiseringsteknikker anvendes til at give brugerne resultatet af data mining.
Summary
Datapræparationsmetoderne sammen med data mining-opgaverne fuldender data mining-processen som sådan. Data mining-processen er ikke så enkel, som vi forklarer. Hver data mining-proces står over for en række udfordringer og problemer i det virkelige livsscenarie og uddrager potentielt nyttige oplysninger.