Esittely
Kokonaista tiedonlouhintaprosessia ei voida toteuttaa yhdessä vaiheessa. Toisin sanoen, suurista tietomääristä ei voi saada tarvittavaa tietoa noin yksinkertaisesti. Se on hyvin monimutkaisempi prosessi kuin luulemme, johon sisältyy useita prosesseja. Prosessit, joihin kuuluvat datan puhdistus, datan integrointi, datan valinta, datan muunnos, datan louhinta, kuvioiden arviointi ja tiedon esittäminen, on suoritettava annetussa järjestyksessä.
Datanlouhintaprosessien tyypit
Erilaiset datanlouhintaprosessit voidaan luokitella kahteen tyyppiin: datan valmisteluun tai datan esikäsittelyyn ja datan louhintaan. Itse asiassa neljä ensimmäistä prosessia, jotka ovat tietojen puhdistus, tietojen integrointi, tietojen valinta ja tietojen muuntaminen, katsotaan tietojen valmisteluprosesseiksi. Kolme viimeistä prosessia, joihin kuuluvat tiedonlouhinta, mallien arviointi ja tiedon esittäminen, on integroitu yhdeksi prosessiksi, jota kutsutaan tiedonlouhinnaksi.
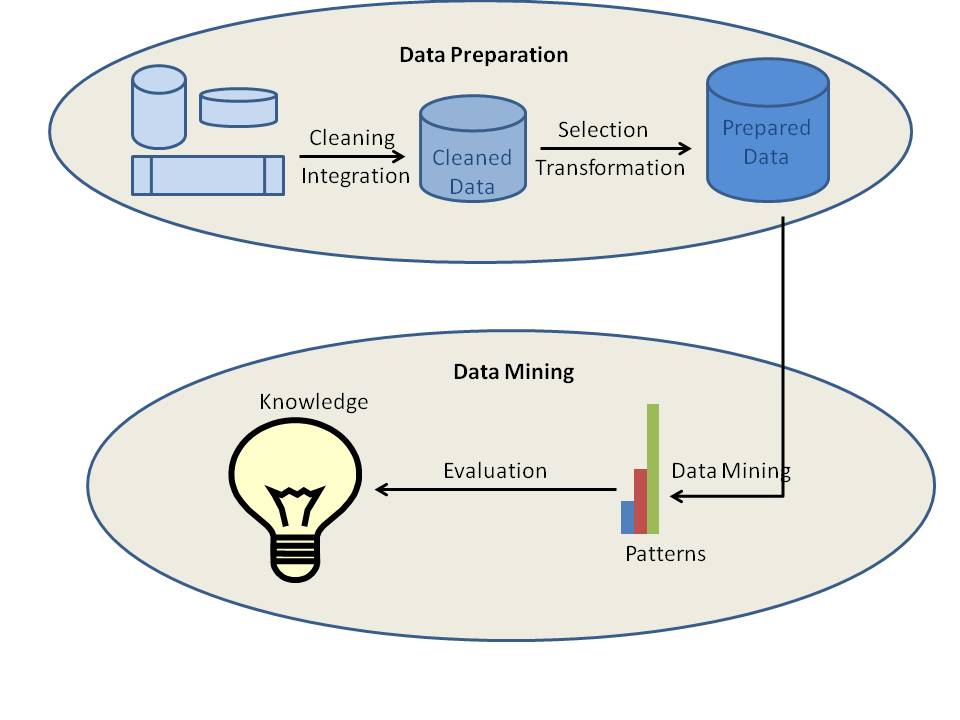
a) Datan puhdistus
Datan puhdistus on prosessi, jossa data puhdistetaan. Reaalimaailman data on yleensä epätäydellistä, meluisaa ja epäjohdonmukaista. Tietolähteissä olevista tiedoista saattaa puuttua attribuuttiarvoja, kiinnostavia tietoja jne. Haluat esimerkiksi asiakkaiden demografiset tiedot, ja mitä jos käytettävissä olevissa tiedoissa ei ole asiakkaiden sukupuolta tai ikää koskevia attribuutteja? Silloin tiedot ovat tietenkin epätäydellisiä. Joskus tiedot saattavat sisältää virheitä tai poikkeamia. Esimerkki on ikäattribuutti, jonka arvo on 200. On selvää, että ikäarvo on tässä tapauksessa väärä. Tiedot voivat olla myös epäjohdonmukaisia. Esimerkiksi työntekijän nimi saattaa olla tallennettu eri tavalla eri tietotaulukoihin tai asiakirjoihin. Tässä tapauksessa tiedot ovat epäjohdonmukaisia. Jos tiedot eivät ole puhtaita, tiedonlouhinnan tulokset eivät olisi luotettavia eivätkä tarkkoja.
Tietojen puhdistamiseen liittyy useita tekniikoita, kuten puuttuvien arvojen täyttäminen manuaalisesti, yhdistetty tietokoneen ja ihmisen suorittama tarkastus jne. Tiedonpuhdistusprosessin tuloksena saadaan asianmukaisesti puhdistettua dataa.
b) Datan integrointi
Datan integrointi on prosessi, jossa eri tietolähteistä saadut tiedot integroidaan yhdeksi. Tiedot sijaitsevat eri muodoissa eri paikoissa. Tiedot voivat olla tallennettuna tietokantoihin, tekstitiedostoihin, taulukkolaskentaohjelmiin, asiakirjoihin, datakuutioihin, Internetiin ja niin edelleen. Tietojen integrointi on todella monimutkainen ja hankala tehtävä, koska eri lähteistä peräisin olevat tiedot eivät yleensä vastaa toisiaan. Oletetaan, että taulukko A sisältää kokonaisuuden nimeltä customer_id, kun taas toinen taulukko B sisältää kokonaisuuden nimeltä number. On todella vaikeaa varmistaa, viittaavatko nämä kaksi oliota samaan arvoon vai eivät. Metatietoja voidaan käyttää tehokkaasti virheiden vähentämiseen tietojen integrointiprosessissa. Toinen ongelma on tietojen päällekkäisyys. Sama tieto saattaa olla saatavilla saman tietokannan eri taulukoissa tai jopa eri tietolähteissä. Tietojen integroinnilla pyritään vähentämään redundanssia mahdollisimman paljon vaikuttamatta tietojen luotettavuuteen.
c) Tietojen valinta
Tiedonlouhintaprosessi vaatii suuria määriä historiallisia tietoja analysoitavaksi. Niinpä yleensä integroitua dataa sisältävä tietovarasto sisältää paljon enemmän dataa kuin todellisuudessa tarvitaan. Käytettävissä olevasta datasta on valittava ja tallennettava kiinnostava data. Datan valinta on prosessi, jossa analyysin kannalta olennainen data haetaan tietokannasta.
d) Datan muuntaminen
Datan muuntaminen on prosessi, jossa data muunnetaan ja yhdistetään erilaisiin, louhintaan soveltuviin muotoihin. Tietojen muuntamiseen kuuluu yleensä normalisointi, aggregointi, yleistäminen jne. Esimerkiksi tietokokonaisuus, joka on saatavilla muodossa “-5, 37, 100, 89, 78”, voidaan muuntaa muotoon “-0,05, 0,37, 1,00, 0,89, 0,78”. Tällöin data soveltuu paremmin tiedonlouhintaan. Tietojen integroinnin jälkeen käytettävissä olevat tiedot ovat valmiita tiedonlouhintaa varten.
e) Tiedonlouhinta
Datanlouhinta on ydinprosessi, jossa sovelletaan useita monimutkaisia ja älykkäitä menetelmiä kuvioiden poimimiseksi tiedoista. Tiedonlouhintaprosessi sisältää useita tehtäviä, kuten assosiaatio, luokittelu, ennustaminen, klusterointi, aikasarja-analyysi ja niin edelleen.
f) Kuvioiden arviointi
Kuvioiden arvioinnissa tunnistetaan todella kiinnostavat kuviot, jotka edustavat tietämystä erityyppisten kiinnostavuusmittojen perusteella. Kuviota pidetään kiinnostavana, jos se on potentiaalisesti hyödyllinen, helposti ihmisten ymmärrettävissä, vahvistaa jonkin hypoteesin, jonka joku haluaa vahvistaa, tai kelpaa uuteen dataan tietyllä varmuudella.
g) Tiedon esittäminen
Datasta louhittu tieto on esitettävä käyttäjälle houkuttelevalla tavalla. Erilaisia tiedon esittämis- ja visualisointitekniikoita sovelletaan, jotta tiedonlouhinnan tuotos voidaan tarjota käyttäjille.
Yhteenveto
Datanvalmistusmenetelmät yhdessä tiedonlouhintatehtävien kanssa viimeistelevät tiedonlouhintaprosessin sellaisenaan. Tiedonlouhintaprosessi ei ole niin yksinkertainen kuin selitämme. Jokainen tiedonlouhintaprosessi kohtaa useita haasteita ja ongelmia tosielämän skenaariossa ja poimii potentiaalisesti hyödyllistä tietoa.