Introduktion
Hela processen för datautvinning kan inte slutföras i ett enda steg. Med andra ord kan du inte få den nödvändiga informationen från de stora datamängderna så enkelt som det är. Det är en mycket komplex process än vad vi tror som inbegriper ett antal processer. Processerna inklusive datarengöring, dataintegration, dataval, datatransformation, datautvinning, mönsterutvärdering och kunskapsrepresentation ska slutföras i den givna ordningen.
Typer av datautvinningsprocesser
De olika datautvinningsprocesserna kan klassificeras i två typer: dataförberedelse eller förbehandling av data och datautvinning. De fyra första processerna, dvs. datarengöring, dataintegration, dataval och datatransformation, betraktas som dataförberedande processer. De tre sista processerna, som är datautvinning, utvärdering av mönster och kunskapsrepresentation, är integrerade i en process som kallas datautvinning.
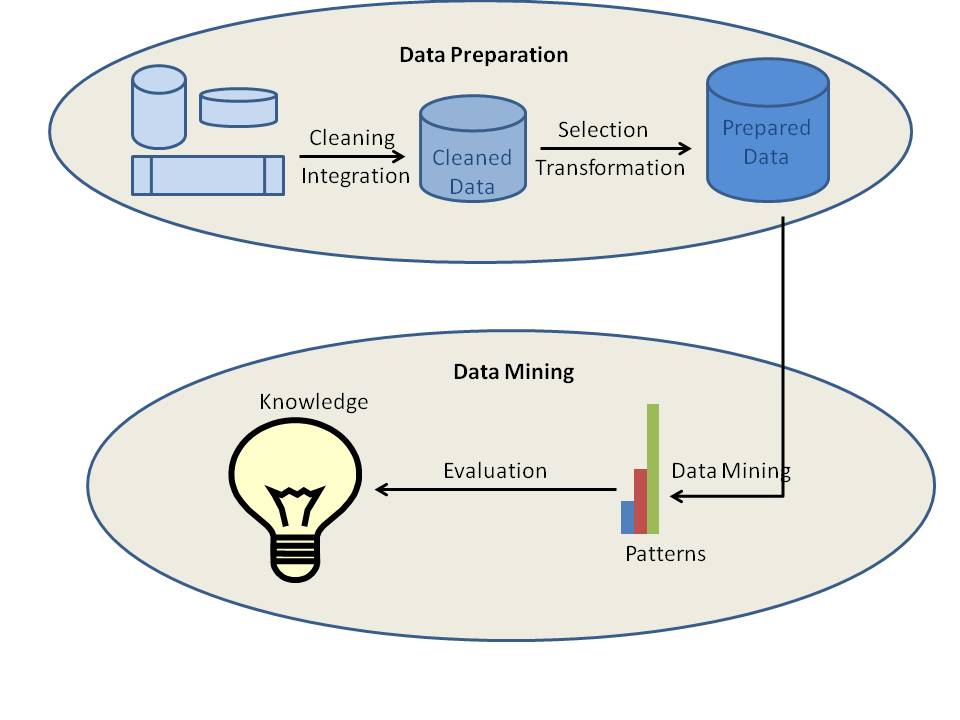
a) Datarengöring
Datarengöring är den process där data rensas. Data i den verkliga världen är normalt ofullständiga, bullriga och inkonsekventa. De data som finns tillgängliga i datakällor kan sakna attributvärden, data av intresse osv. Du vill till exempel ha demografiska uppgifter om kunder, men vad händer om de tillgängliga uppgifterna inte innehåller attribut för kundernas kön eller ålder? Då är uppgifterna naturligtvis ofullständiga. Ibland kan uppgifterna innehålla fel eller avvikelser. Ett exempel är ett attribut för ålder med värdet 200. Det är uppenbart att åldersvärdet är fel i det här fallet. Uppgifterna kan också vara inkonsekventa. En anställds namn kan till exempel lagras på olika sätt i olika datatabeller eller dokument. Här är uppgifterna inkonsekventa. Om uppgifterna inte är rena skulle resultaten av datautvinningen varken vara tillförlitliga eller korrekta.
Rensning av data omfattar ett antal tekniker, inklusive att fylla i de saknade värdena manuellt, kombinerad dator- och mänsklig inspektion osv. Resultatet av datarengöringsprocessen är korrekt rengjorda data.
b) Dataintegration
Dataintegration är en process där data från olika datakällor integreras till en enda. Data finns i olika format på olika platser. Data kan lagras i databaser, textfiler, kalkylblad, dokument, datakuber, Internet och så vidare. Dataintegration är en mycket komplex och svår uppgift eftersom data från olika källor inte stämmer överens normalt sett. Antag att en tabell A innehåller en enhet som heter customer_id medan en annan tabell B innehåller en enhet som heter number. Det är verkligen svårt att säkerställa att båda dessa enheter hänvisar till samma värde eller inte. Metadata kan användas effektivt för att minska felen i dataintegrationsprocessen. Ett annat problem som man ställs inför är dataredundans. Samma data kan finnas i olika tabeller i samma databas eller till och med i olika datakällor. Dataintegration försöker minska redundansen till högsta möjliga nivå utan att påverka uppgifternas tillförlitlighet.
c) Dataval
Data mining-processen kräver stora volymer av historiska data för analys. Så vanligtvis innehåller datalagret med integrerade data mycket mer data än vad som egentligen behövs. Från de tillgängliga uppgifterna måste data av intresse väljas ut och lagras. Dataurval är den process där de data som är relevanta för analysen hämtas från databasen.
d) Datatransformation
Datatatransformation är processen att omvandla och konsolidera data till olika former som är lämpliga för gruvdrift. Datatransformation omfattar normalt normalisering, aggregering, generalisering osv. Till exempel kan en datamängd som finns som “-5, 37, 100, 89, 78” omvandlas till “-0,05, 0,37, 1,00, 0,89, 0,78”. Här blir data mer lämpliga för datautvinning. Efter dataintegration är de tillgängliga uppgifterna redo för datautvinning.
e) Datautvinning
Datautvinning är den centrala process där ett antal komplexa och intelligenta metoder tillämpas för att extrahera mönster från data. Data mining-processen omfattar ett antal uppgifter som association, klassificering, förutsägelse, klustring, tidsserieanalys och så vidare.
f) Mönsterutvärdering
Mönsterutvärderingen identifierar de verkligt intressanta mönstren som representerar kunskap baserat på olika typer av mått för intressanthet. Ett mönster anses vara intressant om det är potentiellt användbart, lättförståeligt för människor, om det bekräftar en hypotes som någon vill bekräfta eller om det är giltigt för nya data med en viss grad av säkerhet.
g) Kunskapsrepresentation
Informationen som utvinns ur data måste presenteras för användaren på ett tilltalande sätt. Olika tekniker för kunskapsrepresentation och visualisering tillämpas för att ge användarna resultatet av datautvinning.
Sammanfattning
Databeredningsmetoderna tillsammans med datautvinningsuppgifterna fullbordar datautvinningsprocessen som sådan. Datautvinningsprocessen är inte så enkel som vi förklarar. Varje datautvinningsprocess möter ett antal utmaningar och problem i verkliga scenarier och extraherar potentiellt användbar information.