Introducción
Todo el proceso de minería de datos no se puede completar en un solo paso. En otras palabras, no se puede obtener la información requerida de los grandes volúmenes de datos así de simple. Es un proceso muy complejo de lo que pensamos que implica una serie de procesos. Los procesos que incluyen la limpieza de datos, la integración de datos, la selección de datos, la transformación de datos, la minería de datos, la evaluación de patrones y la representación del conocimiento deben ser completados en el orden dado.
Tipos de procesos de minería de datos
Los diferentes procesos de minería de datos se pueden clasificar en dos tipos: la preparación de datos o preprocesamiento de datos y la minería de datos. De hecho, los cuatro primeros procesos, que son la limpieza de datos, la integración de datos, la selección de datos y la transformación de datos, se consideran como procesos de preparación de datos. Los tres últimos procesos, que incluyen la minería de datos, la evaluación de patrones y la representación del conocimiento, se integran en un proceso llamado minería de datos.
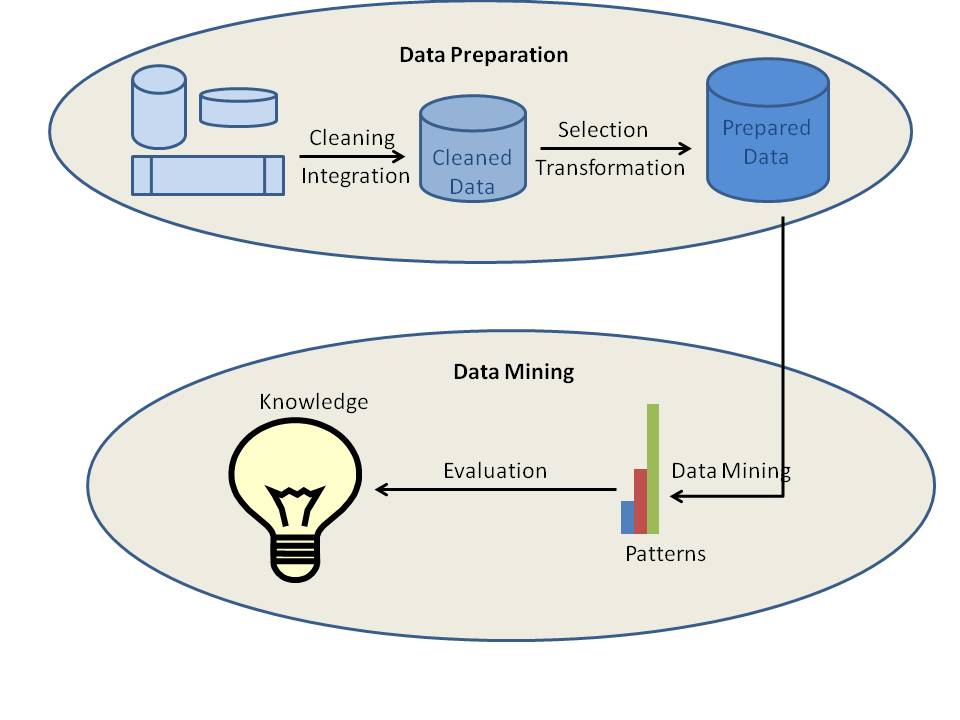
a) Limpieza de datos
La limpieza de datos es el proceso en el que los datos se limpian. Los datos en el mundo real son normalmente incompletos, ruidosos e inconsistentes. Los datos disponibles en las fuentes de datos pueden carecer de valores de atributos, datos de interés, etc. Por ejemplo, usted quiere los datos demográficos de los clientes y ¿qué pasa si los datos disponibles no incluyen atributos para el género o la edad de los clientes? Entonces, los datos están, por supuesto, incompletos. A veces los datos pueden contener errores o valores atípicos. Un ejemplo es un atributo de edad con valor 200. Es obvio que el valor de la edad es erróneo en este caso. Los datos también pueden ser incoherentes. Por ejemplo, el nombre de un empleado puede estar almacenado de forma diferente en distintas tablas de datos o documentos. En este caso, los datos son incoherentes. Si los datos no están limpios, los resultados de la minería de datos no serán fiables ni precisos.
La limpieza de datos implica una serie de técnicas que incluyen rellenar los valores que faltan manualmente, la inspección combinada de ordenadores y humanos, etc. El resultado del proceso de limpieza de datos son datos adecuadamente limpiados.
b) Integración de datos
La integración de datos es el proceso en el que los datos de diferentes fuentes de datos se integran en uno solo. Los datos se encuentran en diferentes formatos y en diferentes lugares. Los datos pueden estar almacenados en bases de datos, archivos de texto, hojas de cálculo, documentos, cubos de datos, Internet, etc. La integración de datos es una tarea realmente compleja y difícil porque los datos de diferentes fuentes no coinciden normalmente. Supongamos que una tabla A contiene una entidad llamada customer_id mientras que otra tabla B contiene una entidad llamada number. Es realmente difícil asegurar que ambas entidades se refieren al mismo valor o no. Los metadatos pueden utilizarse eficazmente para reducir los errores en el proceso de integración de datos. Otro problema que se plantea es la redundancia de datos. Los mismos datos pueden estar disponibles en diferentes tablas de la misma base de datos o incluso en diferentes fuentes de datos. La integración de datos intenta reducir la redundancia al máximo nivel posible sin afectar a la fiabilidad de los datos.
c) Selección de datos
El proceso de minería de datos requiere grandes volúmenes de datos históricos para su análisis. Así, normalmente el repositorio de datos con datos integrados contiene muchos más datos de los que realmente se necesitan. De los datos disponibles, es necesario seleccionar y almacenar los datos de interés. La selección de datos es el proceso en el que los datos relevantes para el análisis se recuperan de la base de datos.
d) Transformación de datos
La transformación de datos es el proceso de transformar y consolidar los datos en diferentes formas que sean adecuadas para la minería. La transformación de datos normalmente implica la normalización, la agregación, la generalización, etc. Por ejemplo, un conjunto de datos disponible como “-5, 37, 100, 89, 78” puede transformarse como “-0,05, 0,37, 1,00, 0,89, 0,78”. En este caso, los datos son más adecuados para la minería de datos. Después de la integración de datos, los datos disponibles están listos para la minería de datos.
e) Minería de datos
La minería de datos es el proceso central en el que se aplican una serie de métodos complejos e inteligentes para extraer patrones de los datos. El proceso de minería de datos incluye una serie de tareas como la asociación, la clasificación, la predicción, la agrupación, el análisis de series temporales, etc.
f) Evaluación de patrones
La evaluación de patrones identifica los patrones verdaderamente interesantes que representan el conocimiento basado en diferentes tipos de medidas de interés. Un patrón se considera interesante si es potencialmente útil, fácilmente comprensible por los humanos, valida alguna hipótesis que alguien quiere confirmar o es válido sobre nuevos datos con cierto grado de certeza.
g) Representación del conocimiento
La información extraída de los datos necesita ser presentada al usuario de una manera atractiva. Diferentes técnicas de representación y visualización del conocimiento se aplican para proporcionar el resultado de la minería de datos a los usuarios.
Resumen
Los métodos de preparación de datos junto con las tareas de minería de datos completan el proceso de minería de datos como tal. El proceso de minería de datos no es tan sencillo como lo explicamos. Cada proceso de minería de datos se enfrenta a una serie de desafíos y problemas en el escenario de la vida real y extrae información potencialmente útil.