Introduction
Het hele proces van data mining kan niet in een enkele stap worden voltooid. Met andere woorden, je kunt de benodigde informatie niet zo eenvoudig uit de grote hoeveelheden gegevens halen. Het is een zeer complex proces dan we denken waarbij een aantal processen komt kijken. De processen, waaronder het opschonen van gegevens, gegevensintegratie, gegevensselectie, gegevenstransformatie, datamining, patroonevaluatie en kennisrepresentatie, moeten in de gegeven volgorde worden voltooid.
Typen dataminingprocessen
Verschillende dataminingprocessen kunnen worden ingedeeld in twee typen: datavoorbereiding of datavoorbewerking en datamining. In feite worden de eerste vier processen, namelijk gegevensreiniging, gegevensintegratie, gegevensselectie en gegevenstransformatie, beschouwd als datavoorbereidingsprocessen. De laatste drie processen, waaronder datamining, patroonevaluatie en kennisrepresentatie, zijn geïntegreerd in één proces dat datamining wordt genoemd.
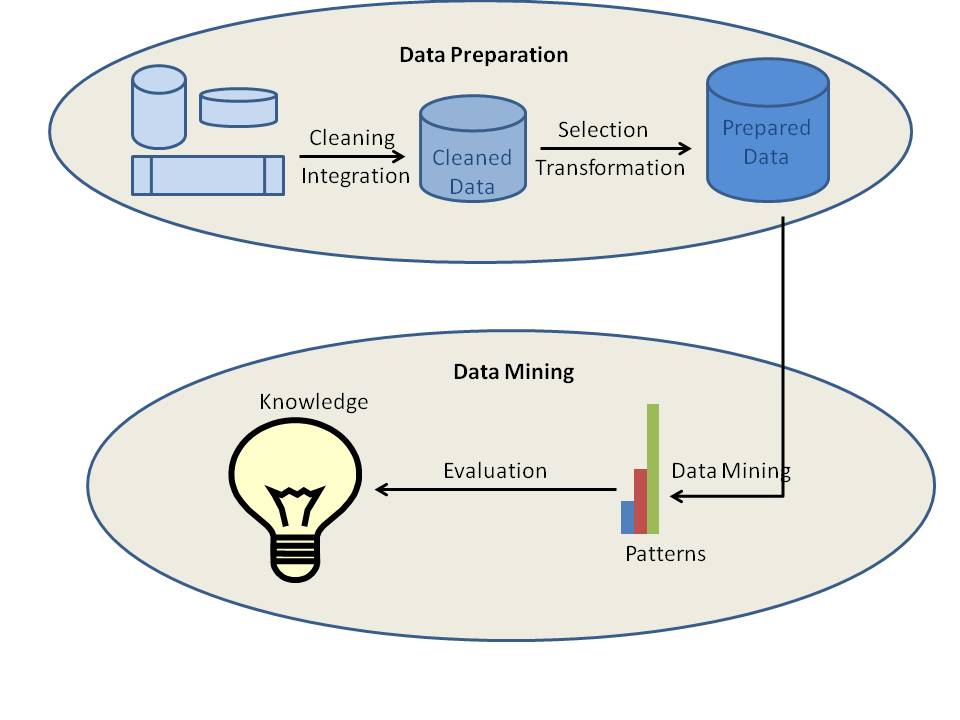
a) Dataschoning
Dataschoning is het proces waarbij de gegevens worden opgeschoond. Gegevens in de echte wereld zijn gewoonlijk onvolledig, ruisachtig en inconsistent. De beschikbare gegevens in gegevensbronnen kunnen ontbreken attribuut waarden, gegevens van belang, enz. Bijvoorbeeld, u wilt de demografische gegevens van klanten en wat als de beschikbare gegevens geen attributen bevatten voor het geslacht of de leeftijd van de klanten? Dan zijn de gegevens natuurlijk onvolledig. Soms kunnen de gegevens fouten of uitschieters bevatten. Een voorbeeld is een leeftijdsattribuut met waarde 200. Het is duidelijk dat de leeftijdswaarde in dit geval fout is. De gegevens kunnen ook inconsistent zijn. Zo kan de naam van een werknemer in verschillende gegevenstabellen of documenten verschillend zijn opgeslagen. Hier zijn de gegevens inconsistent. Als de gegevens niet schoon zijn, zouden de dataminingresultaten noch betrouwbaar, noch accuraat zijn.
Bij het opschonen van gegevens wordt een aantal technieken gebruikt, waaronder het handmatig invullen van ontbrekende waarden, gecombineerde computer- en menselijke inspectie, enz. De output van het proces van gegevensopschoning is adequaat opgeschoonde gegevens.
b) Gegevensintegratie
Gegevensintegratie is het proces waarbij gegevens uit verschillende gegevensbronnen worden geïntegreerd tot één geheel. Gegevens bevinden zich in verschillende formaten op verschillende locaties. Gegevens kunnen zijn opgeslagen in databanken, tekstbestanden, spreadsheets, documenten, gegevenskubussen, internet enzovoort. Data-integratie is een echt complexe en lastige taak omdat gegevens uit verschillende bronnen normaal gezien niet overeenstemmen. Stel dat een tabel A een entiteit bevat met de naam customer_id en een andere tabel B een entiteit met de naam number. Het is echt moeilijk om ervoor te zorgen dat beide entiteiten al dan niet naar dezelfde waarde verwijzen. Metadata kunnen doeltreffend worden gebruikt om fouten in het data-integratieproces te beperken. Een ander probleem is de redundantie van de gegevens. Dezelfde gegevens kunnen beschikbaar zijn in verschillende tabellen in dezelfde database of zelfs in verschillende gegevensbronnen. Bij data-integratie wordt getracht de redundantie zoveel mogelijk te beperken zonder de betrouwbaarheid van de gegevens aan te tasten.
c) Gegevensselectie
Data mining-processen vereisen grote hoeveelheden historische gegevens voor analyse. Meestal bevat het gegevensarchief met geïntegreerde gegevens dus veel meer gegevens dan eigenlijk nodig zijn. Uit de beschikbare gegevens moeten de gegevens worden geselecteerd en opgeslagen die van belang zijn. Gegevensselectie is het proces waarbij de voor de analyse relevante gegevens uit de databank worden gehaald.
d) Gegevenstransformatie
Gegegevenstransformatie is het proces waarbij de gegevens worden getransformeerd en geconsolideerd in verschillende vormen die geschikt zijn voor mijnbouw. Bij gegevenstransformatie is normalisatie, aggregatie, generalisatie enz. normaal. Bijvoorbeeld, een gegevensreeks die beschikbaar is als “-5, 37, 100, 89, 78” kan worden getransformeerd als “-0,05, 0,37, 1,00, 0,89, 0,78”. Hier worden de gegevens meer geschikt voor datamining. Na gegevensintegratie zijn de beschikbare gegevens klaar voor datamining.
e) Datamining
Datamining is het kernproces waarbij een aantal complexe en intelligente methoden worden toegepast om patronen uit gegevens te extraheren. Het dataminingproces omvat een aantal taken zoals associatie, classificatie, voorspelling, clustering, tijdreeksanalyse enzovoort.
f) Patroonevaluatie
De patroonevaluatie identificeert de werkelijk interessante patronen die kennis vertegenwoordigen op basis van verschillende soorten interessantheidsmaatstaven. Een patroon wordt als interessant beschouwd als het potentieel nuttig is, gemakkelijk door mensen kan worden begrepen, een of andere hypothese valideert die iemand wil bevestigen of met enige mate van zekerheid op nieuwe gegevens valideert.
g) Kennisrepresentatie
De uit de gegevens gedolven informatie moet op een aantrekkelijke manier aan de gebruiker worden gepresenteerd. Er worden verschillende kennisrepresentatie- en visualisatietechnieken toegepast om de output van datamining aan de gebruikers te presenteren.
Samenvatting
De methoden voor de voorbereiding van de gegevens samen met de dataminingtaken maken het dataminingproces als zodanig compleet. Het dataminingproces is niet zo eenvoudig als wij het uitleggen. Elk dataminingproces wordt geconfronteerd met een aantal uitdagingen en problemen in een reëel scenario en extraheert potentieel nuttige informatie.