Introduction
Cały proces eksploracji danych nie może być zakończony w jednym kroku. Innymi słowy, nie można uzyskać wymaganych informacji z dużej ilości danych w tak prosty sposób. Jest to bardzo złożony proces, na który składa się wiele procesów. Procesy obejmujące czyszczenie danych, integrację danych, selekcję danych, transformację danych, eksplorację danych, ocenę wzorców i reprezentację wiedzy muszą być zakończone w określonej kolejności.
Typy procesów eksploracji danych
Różne procesy eksploracji danych mogą być sklasyfikowane w dwóch typach: przygotowanie danych lub wstępne przetwarzanie danych i eksploracja danych. Pierwsze cztery procesy, takie jak czyszczenie danych, integracja danych, selekcja danych i transformacja danych, są uważane za procesy przygotowania danych. Ostatnie trzy procesy, w tym eksploracja danych, ocena wzorców i reprezentacja wiedzy są zintegrowane w jeden proces zwany eksploracją danych.
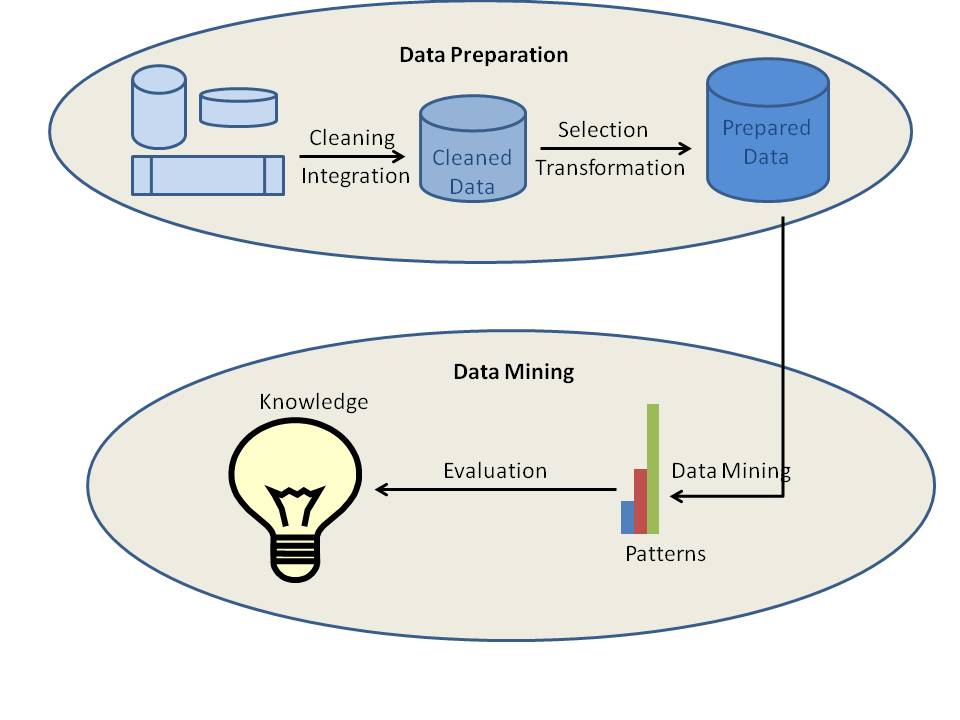
a) Czyszczenie danych
Czyszczenie danych jest procesem, w którym dane zostają oczyszczone. Dane w świecie rzeczywistym są zazwyczaj niekompletne, zaszumione i niespójne. Dane dostępne w źródłach danych mogą być pozbawione wartości atrybutów, danych zainteresowania itp. Na przykład, chcesz uzyskać dane demograficzne klientów, a co jeśli dostępne dane nie zawierają atrybutów dla płci lub wieku klientów? Wtedy dane są oczywiście niekompletne. Czasami dane mogą zawierać błędy lub wartości odstające. Przykładem jest atrybut wiek o wartości 200. Jest oczywiste, że w tym przypadku wartość wieku jest błędna. Dane mogą być również niespójne. Na przykład, nazwisko pracownika może być przechowywane w różny sposób w różnych tabelach danych lub dokumentach. W tym przypadku dane są niespójne. Jeśli dane nie są czyste, wyniki eksploracji danych nie będą ani wiarygodne ani dokładne.
Czyszczenie danych obejmuje wiele technik, w tym ręczne wypełnianie brakujących wartości, połączoną kontrolę komputerową i ludzką, itp. Wyjściem procesu czyszczenia danych jest odpowiednio oczyszczone dane.
b) Integracja danych
Integracja danych jest procesem, w którym dane z różnych źródeł danych są zintegrowane w jeden. Dane są przechowywane w różnych formatach, w różnych miejscach. Dane mogą być przechowywane w bazach danych, plikach tekstowych, arkuszach kalkulacyjnych, dokumentach, kostkach danych, Internecie i tak dalej. Integracja danych jest naprawdę skomplikowanym i trudnym zadaniem, ponieważ dane z różnych źródeł nie pasują do siebie w normalny sposób. Załóżmy, że tabela A zawiera encję o nazwie customer_id, gdzie jako inna tabela B zawiera encję o nazwie numer. Naprawdę trudno jest się upewnić, czy obie te encje odnoszą się do tej samej wartości czy nie. Metadane mogą być efektywnie wykorzystane w celu redukcji błędów w procesie integracji danych. Innym problemem jest redundancja danych. Te same dane mogą być dostępne w różnych tabelach w tej samej bazie danych lub nawet w różnych źródłach danych. Integracja danych stara się zredukować redundancję do maksymalnego możliwego poziomu bez wpływu na wiarygodność danych.
c) Wybór danych
Proces eksploracji danych wymaga dużych ilości danych historycznych do analizy. Dlatego zazwyczaj repozytorium danych z danymi zintegrowanymi zawiera znacznie więcej danych niż jest to faktycznie wymagane. Z dostępnych danych należy wybrać i przechowywać te, które nas interesują. Selekcja danych jest procesem, w którym dane istotne dla analizy są pobierane z bazy danych.
d) Transformacja danych
Transformacja danych jest procesem przekształcania i konsolidacji danych do różnych form, które są odpowiednie do eksploracji. Transformacja danych zazwyczaj obejmuje normalizację, agregację, generalizację itp. Na przykład, zbiór danych dostępny jako “-5, 37, 100, 89, 78” może być przekształcony jako “-0.05, 0.37, 1.00, 0.89, 0.78”. W tym przypadku dane stają się bardziej odpowiednie do eksploracji danych. Po integracji danych, dostępne dane są gotowe do eksploracji danych.
e) Eksploracja danych
Eksploracja danych jest podstawowym procesem, w którym stosuje się szereg złożonych i inteligentnych metod w celu wydobycia wzorców z danych. Proces eksploracji danych obejmuje szereg zadań, takich jak asocjacja, klasyfikacja, predykcja, grupowanie, analiza szeregów czasowych i tak dalej.
f) Ocena wzorców
Ocena wzorców identyfikuje naprawdę interesujące wzorce reprezentujące wiedzę w oparciu o różne rodzaje miar interesowności. Wzorzec jest uważany za interesujący, jeśli jest potencjalnie użyteczny, łatwo zrozumiały dla człowieka, potwierdza jakąś hipotezę, którą ktoś chce potwierdzić lub jest ważny na nowych danych z pewnym stopniem pewności.
g) Reprezentacja wiedzy
Informacje wydobyte z danych muszą być przedstawione użytkownikowi w atrakcyjny sposób. Różne techniki reprezentacji wiedzy i wizualizacji są stosowane w celu dostarczenia użytkownikom wyników eksploracji danych.
Podsumowanie
Metody przygotowania danych wraz z zadaniami eksploracji danych uzupełniają proces eksploracji danych jako taki. Proces eksploracji danych nie jest tak prosty, jak to wyjaśniamy. Każdy proces eksploracji danych napotyka na szereg wyzwań i problemów w realnym scenariuszu życia i wydobywa potencjalnie użyteczne informacje.
.